Applying Deep
Reinforcement Learning to Improve Throughput and Reduce Collision Rate in IEEE
802.11 Networks
I will provide the basic simulation code for my paper. If you use my work, please cite my paper in your work.
C. Ke and L. Astuti, "Applying
Deep Reinforcement Learning to Improve Throughput and Reduce Collision Rate in
IEEE 802.11 Networks," KSII Transactions on Internet and Information
Systems, vol. 16, no. 1, pp. 334-349, 2022. DOI: 10.3837/tiis.2022.01.019. (SCI)
By the way, the parameters used in the code is
for IEEE 802.11b environment. Also, the DQN was implemented using PARL framework. You can
download the VM.
(user/user, root/ubuntu) You can directly run the following code in this VM.
CSMACA
|
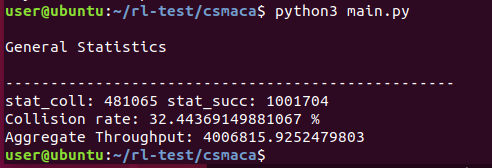
import numpy as np import random _n=50 # number of nodes _simTime=2000 # sec rate=11 # 11, 5.5, 2 or 1 Mbps _cwmin=32 _cwmax=1024 rtsmode=0 #0: data->ack; 1:rts->cts->data->ack SIFS=10 DIFS=50 EIFS=SIFS+DIFS+192+112 SLOT=20 M=1000000 _pktSize=1000 # bytes stat_succ=0 stat_coll=0 stat_pkts=np.zeros(_n) cw=np.zeros(_n) bo=np.zeros(_n) now=0.0 def init_bo(): for i in range(0,_n): cw[i]=_cwmin bo[i]=random.randint(0,_cwmax)%cw[i] #print("cw[",i,"]=",cw[i]," bo[",i,"]=",bo[i]) def Trts(): time=192+(20*8)/1 return time def Tcts(): time=192+(14*8)/1 return time def Tdata(): global rate time=192+((_pktSize+28)*8.0)/rate return time def Tack(): time=192+(14*8.0)/1 return time def getMinBoAllStationsIndex(): index=0 min=bo[index] for i in range(0,_n): if bo[i]<min: index=i min=bo[index] return index def getCountMinBoAllStations(min): count=0 for i in range(0,_n): if(bo[i]==min): count+=1 return count def subMinBoFromAll(min,count): global _cwmin,_cwmax for i in range(0,_n): if bo[i]<min: print("<Error> min=",min," bo=",bo[i]) exit(1) if(bo[i]>min): bo[i]-=min elif bo[i]==min: if count==1: cw[i]=_cwmin bo[i] = random.randint(0, _cwmax) % cw[i] elif count>1: if(cw[i]<_cwmax): cw[i]*=2 else: cw[i]=_cwmax bo[i] = random.randint(0, _cwmax) % cw[i] else: print("<Error> count=",count) exit(1) def setStats(min,index,count): global stat_succ,stat_coll if count==1: stat_pkts[index]+=1 stat_succ+=1 else: stat_coll+=1 for i in range(0,_n): if bo[i]<min: print("<Error> min=", min, " bo=", bo[i]) exit(1) #elif bo[i]==min: # print("Collision with min=", min) def setNow(min,count): global M, now, SIFS, DIFS, EIFS, SLOT if count==1: now+=DIFS/M now+=min*SLOT/M if(rtsmode==1): now+=Trts()/M; now+=SIFS/M now+=Tcts()/M now+=SIFS/M now+=Tdata()/M now+=SIFS/M now+=Tack()/M elif count>1: now+=DIFS/M now+=min*SLOT/M if rtsmode==1: now+=Trts()/M; now+=EIFS/M else: now+=Tdata()/M now+=EIFS/M else: print("<Error> count=", count) exit(1) def resolve(): index=getMinBoAllStationsIndex() min=bo[index] count=getCountMinBoAllStations(min) setNow(min, count) setStats(min, index, count) subMinBoFromAll(min, count) def printStats(): global stat_succ, stat_coll, stat_pkts print("\nGeneral Statistics\n") print("-"*50) numPkts=0 for i in range(0,_n): numPkts+=stat_pkts[i] print("stat_coll:", stat_coll, "stat_succ:", stat_succ) print("Collision rate:", stat_coll/(stat_succ+stat_coll)*100, "%") print("Aggregate Throughput:", numPkts*(_pktSize*8.0)/now) def main(): global now, _simTime random.seed(1) init_bo() while now < _simTime: resolve() printStats() main() |
Execution
CCOD-DQN
|
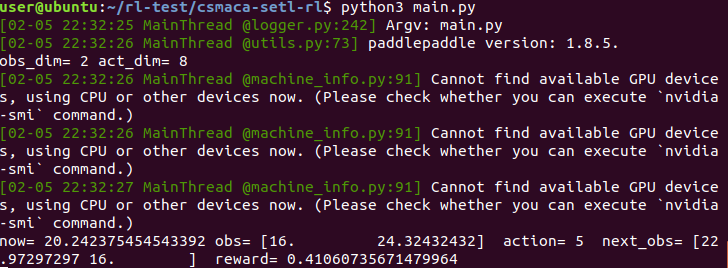
# -*- coding: UTF-8 -*- import numpy as np import random import os import parl from parl import layers import copy import paddle.fluid as fluid import collections MEMORY_SIZE = 20000 MEMORY_WARMUP_SIZE = 200 BATCH_SIZE = 32 LEARNING_RATE = 0.001 GAMMA = 0.9 pre_time=0.0 pre_stat_succ=0 pre_stat_coll=0 _n=50 _simTime=2000 rate=11 _cwmin=32 _cwmax=1024 rtsmode=0 SIFS=10 DIFS=50 EIFS=SIFS+DIFS+192+112 SLOT=20 M=1000000 _pktSize=1000 stat_succ=0 stat_coll=0 stat_pkts=np.zeros(_n) cw=np.zeros(_n) bo=np.zeros(_n) now=0.0 class Model(parl.Model): def __init__(self, act_dim): hid1_size = 128 hid2_size = 128 self.fc1 = layers.fc(size=hid1_size, act='relu') self.fc2 = layers.fc(size=hid2_size, act='relu') self.fc3 = layers.fc(size=act_dim, act=None) def value(self, obs): h1 = self.fc1(obs) h2 = self.fc2(h1) Q = self.fc3(h2) return Q class DQN(parl.Algorithm): def __init__(self, model, act_dim=None, gamma=None, lr=None): self.model = model self.target_model = copy.deepcopy(model) assert isinstance(act_dim, int) assert isinstance(gamma, float) assert isinstance(lr, float) self.act_dim = act_dim self.gamma = gamma self.lr = lr def predict(self, obs): return self.model.value(obs) def learn(self, obs, action, reward, next_obs, terminal): next_pred_value = self.target_model.value(next_obs) best_v = layers.reduce_max(next_pred_value, dim=1) best_v.stop_gradient = True terminal = layers.cast(terminal, dtype='float32') target = reward + (1.0 - terminal) * self.gamma * best_v pred_value = self.model.value(obs) action_onehot = layers.one_hot(action, self.act_dim) action_onehot = layers.cast(action_onehot, dtype='float32')
pred_action_value = layers.reduce_sum( layers.elementwise_mul(action_onehot, pred_value), dim=1) cost = layers.square_error_cost(pred_action_value, target) cost = layers.reduce_mean(cost) optimizer = fluid.optimizer.Adam(learning_rate=self.lr) optimizer.minimize(cost) return cost def sync_target(self): self.model.sync_weights_to(self.target_model) class Agent(parl.Agent): def __init__(self, algorithm, obs_dim, act_dim, e_greed=0.1, e_greed_decrement=0): assert isinstance(obs_dim, int) assert isinstance(act_dim, int) self.obs_dim = obs_dim self.act_dim = act_dim super(Agent, self).__init__(algorithm) self.global_step = 0 self.update_target_steps = 200 self.e_greed = e_greed self.e_greed_decrement = e_greed_decrement def build_program(self): self.pred_program = fluid.Program() self.learn_program = fluid.Program() with fluid.program_guard(self.pred_program): obs = layers.data( name='obs', shape=[self.obs_dim], dtype='float32') self.value = self.alg.predict(obs) with fluid.program_guard(self.learn_program): obs = layers.data( name='obs', shape=[self.obs_dim], dtype='float32') action = layers.data(name='act', shape=[1], dtype='int32') reward = layers.data(name='reward', shape=[], dtype='float32') next_obs = layers.data( name='next_obs', shape=[self.obs_dim], dtype='float32') terminal = layers.data(name='terminal', shape=[], dtype='bool') self.cost = self.alg.learn(obs, action, reward, next_obs, terminal) def sample(self, obs): sample = np.random.rand() if sample < self.e_greed: act = np.random.randint(self.act_dim) else: act = self.predict(obs) self.e_greed = max( 0.01, self.e_greed - self.e_greed_decrement) return act def predict(self, obs): obs = np.expand_dims(obs, axis=0) pred_Q = self.fluid_executor.run( self.pred_program, feed={'obs': obs.astype('float32')}, fetch_list=[self.value])[0] pred_Q = np.squeeze(pred_Q, axis=0) act = np.argmax(pred_Q) return act def learn(self, obs, act, reward, next_obs, terminal):
if self.global_step % self.update_target_steps == 0: self.alg.sync_target() self.global_step += 1 act = np.expand_dims(act, -1) feed = { 'obs': obs.astype('float32'), 'act': act.astype('int32'), 'reward': reward, 'next_obs': next_obs.astype('float32'), 'terminal': terminal } cost = self.fluid_executor.run( self.learn_program, feed=feed, fetch_list=[self.cost])[0] return cost class ReplayMemory(object): def __init__(self, max_size): self.buffer = collections.deque(maxlen=max_size) def append(self, exp): self.buffer.append(exp) def sample(self, batch_size): mini_batch = random.sample(self.buffer, batch_size) obs_batch, action_batch, reward_batch, next_obs_batch, done_batch = [], [], [], [], [] for experience in mini_batch: s, a, r, s_p, done = experience obs_batch.append(s) action_batch.append(a) reward_batch.append(r) next_obs_batch.append(s_p) done_batch.append(done) return np.array(obs_batch).astype('float32'), \ np.array(action_batch).astype('float32'), np.array(reward_batch).astype('float32'),\ np.array(next_obs_batch).astype('float32'), np.array(done_batch).astype('float32') def __len__(self): return len(self.buffer) def init_bo(): for i in range(0,_n): cw[i]=_cwmin bo[i]=random.randint(0,_cwmax)%cw[i]
def Trts(): time=192+(20*8)/1 return time def Tcts(): time=192+(14*8)/1 return time def Tdata(): global rate time=192+((_pktSize+28)*8.0)/rate return time def Tack(): time=192+(14*8.0)/1 return time def getMinBoAllStationsIndex(): index=0 min=bo[index] for i in range(0,_n): if bo[i]<min: index=i min=bo[index] return index def getCountMinBoAllStations(min): count=0 for i in range(0,_n): if(bo[i]==min): count+=1 return count def subMinBoFromAll(min,count): global _cwmin,_cwmax for i in range(0,_n): if bo[i]<min: print("<Error> min=",min," bo=",bo[i]) exit(1) if(bo[i]>min): bo[i]-=min elif bo[i]==min: if count==1: cw[i]=_cwmin bo[i] = random.randint(0, _cwmax) % cw[i] elif count>1: if(cw[i]<_cwmax): cw[i]*=2 else: cw[i]=_cwmax bo[i] = random.randint(0, _cwmax) % cw[i] else: print("<Error> count=",count) exit(1) def setStats(min,index,count): global stat_succ,stat_coll if count==1: stat_pkts[index]+=1 stat_succ+=1 else: stat_coll+=1 for i in range(0,_n): if bo[i]<min: print("<Error> min=", min, " bo=", bo[i]) exit(1)
def setNow(min,count): global M, now, SIFS, DIFS, EIFS, SLOT if count==1: now+=DIFS/M now+=min*SLOT/M if(rtsmode==1): now+=Trts()/M; now+=SIFS/M now+=Tcts()/M now+=SIFS/M now+=Tdata()/M now+=SIFS/M now+=Tack()/M elif count>1: now+=DIFS/M now+=min*SLOT/M if rtsmode==1: now+=Trts()/M; now+=EIFS/M else: now+=Tdata()/M now+=EIFS/M else: print("<Error> count=", count) exit(1) def resolve(): index=getMinBoAllStationsIndex() min=bo[index] count=getCountMinBoAllStations(min) setNow(min, count) setStats(min, index, count) subMinBoFromAll(min, count) def new_resolve(new_cw): global _cwmin,_cwmax _cwmin=new_cw _cwmax=new_cw index=getMinBoAllStationsIndex() min=bo[index] count=getCountMinBoAllStations(min) setNow(min, count) setStats(min, index, count) subMinBoFromAll(min, count) def printStats(): print("\nGeneral Statistics\n") print("-"*50) print("stat_succ:",stat_succ,"stat_coll:",stat_coll) print("Collision rate:", stat_coll/(stat_succ+stat_coll)*100, "%") print("Aggregate Throughput:", (stat_succ)*(_pktSize*8.0)/now) def main(): global _n, now, _simTime, stat_succ, stat_coll, pre_stat_succ, pre_stat_coll, _pktSize, pre_time pre_collision_rate=0.0 random.seed(1) np.random.seed(1) init_bo() obs_dim=2 act_dim=6 print("obs_dim=",obs_dim,"act_dim=",act_dim) model = Model(act_dim=act_dim) algorithm = DQN(model, act_dim=act_dim, gamma=GAMMA, lr=LEARNING_RATE) agent = Agent( algorithm, obs_dim=obs_dim, act_dim=act_dim, e_greed=0.1, e_greed_decrement=1e-6) rpm = ReplayMemory(MEMORY_SIZE) #save_path = './dnq_model.ckpt'
step=0 reward=0.0 state = [0.0, 0.0] show=0 while now < _simTime: while len(rpm) < MEMORY_WARMUP_SIZE: obs = np.array(state) action = agent.sample(obs) new_cw = pow(2, 5 + action) t1=now while True: new_resolve(new_cw) if now - t1 > 0.1: break collision_rate = (stat_coll - pre_stat_coll) / (stat_succ + stat_coll - pre_stat_succ - pre_stat_coll) * 100 thr = (stat_succ - pre_stat_succ) * (_pktSize * 8.0) / (now - pre_time) reward = thr / rate / M next_state=[] next_state.append(pre_collision_rate) next_state.append(collision_rate)
pre_stat_succ = stat_succ pre_stat_coll = stat_coll pre_collision_rate = collision_rate pre_time = now
next_obs=np.array(next_state) done = False rpm.append((obs, action, reward, next_obs, done))
state = next_state
if step%5==0: (batch_obs, batch_action, batch_reward, batch_next_obs, batch_done) = rpm.sample(BATCH_SIZE) train_loss = agent.learn(batch_obs, batch_action, batch_reward, batch_next_obs, batch_done)
obs = np.array(state) action = agent.sample(obs) new_cw = pow(2, 5 + action) t1=now while True: new_resolve(new_cw) if now - t1 > 0.1: break collision_rate = (stat_coll - pre_stat_coll) / (stat_succ + stat_coll - pre_stat_succ - pre_stat_coll) * 100 thr = (stat_succ - pre_stat_succ) * (_pktSize * 8.0) / (now - pre_time) reward = thr / rate / M next_state = [] next_state.append(pre_collision_rate) next_state.append(collision_rate) step += 1 pre_stat_succ = stat_succ pre_stat_coll = stat_coll pre_collision_rate = collision_rate pre_time = now
next_obs = np.array(next_state) done = False rpm.append((obs, action, reward, next_obs, done)) if now > show: print("now=", now, "obs=", obs, " action=", action, " next_obs=", next_obs, " reward=", reward) show+=100 state = next_state printStats() #agent.save(save_path) now=pre_time=0.0 state = [0.0, 0.0] stat_coll=pre_stat_coll=0 stat_succ=pre_stat_succ=0 stat_pkts=np.zeros(_n) while now < 5: obs = np.array(state) action = agent.predict(obs) new_cw = pow(2, 5 + action) print("new_cw=", new_cw) t1=now while True: new_resolve(new_cw) if now - t1 > 0.1: break collision_rate = (stat_coll - pre_stat_coll) / (stat_succ + stat_coll - pre_stat_succ - pre_stat_coll) * 100 thr = (stat_succ - pre_stat_succ) * (_pktSize * 8.0) / (now - pre_time) next_state = [] next_state.append(pre_collision_rate) next_state.append(collision_rate) pre_stat_succ = stat_succ pre_stat_coll = stat_coll pre_collision_rate = collision_rate pre_time = now print("now=", now, " collison rate=",collision_rate," thr=", thr) state = next_state print("="*25, " Evaluation Result:") printStats() main() |
Execution

…………………..

SETL-DQN
|
import numpy as np import random import os import parl from parl import layers import copy import paddle.fluid as fluid import collections MEMORY_SIZE = 20000 MEMORY_WARMUP_SIZE = 200 BATCH_SIZE = 32 LEARNING_RATE = 0.001 GAMMA = 0.9 pre_time=0.0 pre_stat_succ=0 pre_stat_coll=0 _n=50 # number of nodes _simTime=2000 # sec rate=11 # 11, 5.5, 2 or 1 Mbps _cwmin=32 _cwmax=1024 rtsmode=0 #0: data->ack; 1:rts->cts->data->ack cwthreshold=512 SIFS=10 DIFS=50 EIFS=SIFS+DIFS+192+112 SLOT=20 M=1000000 _pktSize=1000 # bytes stat_succ=0 stat_coll=0 stat_pkts=np.zeros(_n) cw=np.zeros(_n) bo=np.zeros(_n) now=0.0 class Model(parl.Model): def __init__(self, act_dim): hid1_size = 128 hid2_size = 128 self.fc1 = layers.fc(size=hid1_size, act='relu') self.fc2 = layers.fc(size=hid2_size, act='relu') self.fc3 = layers.fc(size=act_dim, act=None) def value(self, obs): h1 = self.fc1(obs) h2 = self.fc2(h1) Q = self.fc3(h2) return Q class DQN(parl.Algorithm): def __init__(self, model, act_dim=None, gamma=None, lr=None): self.model = model self.target_model = copy.deepcopy(model) assert isinstance(act_dim, int) assert isinstance(gamma, float) assert isinstance(lr, float) self.act_dim = act_dim self.gamma = gamma self.lr = lr def predict(self, obs): return self.model.value(obs) def learn(self, obs, action, reward, next_obs, terminal): next_pred_value = self.target_model.value(next_obs) best_v = layers.reduce_max(next_pred_value, dim=1) best_v.stop_gradient = True terminal = layers.cast(terminal, dtype='float32') target = reward + (1.0 - terminal) * self.gamma * best_v pred_value = self.model.value(obs) action_onehot = layers.one_hot(action, self.act_dim) action_onehot = layers.cast(action_onehot, dtype='float32')
pred_action_value = layers.reduce_sum( layers.elementwise_mul(action_onehot, pred_value), dim=1) cost = layers.square_error_cost(pred_action_value, target) cost = layers.reduce_mean(cost) optimizer = fluid.optimizer.Adam(learning_rate=self.lr) optimizer.minimize(cost) return cost def sync_target(self): self.model.sync_weights_to(self.target_model) class Agent(parl.Agent): def __init__(self, algorithm, obs_dim, act_dim, e_greed=0.1, e_greed_decrement=0): assert isinstance(obs_dim, int) assert isinstance(act_dim, int) self.obs_dim = obs_dim self.act_dim = act_dim super(Agent, self).__init__(algorithm) self.global_step = 0 self.update_target_steps = 200 self.e_greed = e_greed self.e_greed_decrement = e_greed_decrement def build_program(self): self.pred_program = fluid.Program() self.learn_program = fluid.Program() with fluid.program_guard(self.pred_program): obs = layers.data( name='obs', shape=[self.obs_dim], dtype='float32') self.value = self.alg.predict(obs) with fluid.program_guard(self.learn_program): obs = layers.data( name='obs', shape=[self.obs_dim], dtype='float32') action = layers.data(name='act', shape=[1], dtype='int32') reward = layers.data(name='reward', shape=[], dtype='float32') next_obs = layers.data( name='next_obs', shape=[self.obs_dim], dtype='float32') terminal = layers.data(name='terminal', shape=[], dtype='bool') self.cost = self.alg.learn(obs, action, reward, next_obs, terminal) def sample(self, obs): sample = np.random.rand() if sample < self.e_greed: act = np.random.randint(self.act_dim) else: act = self.predict(obs) self.e_greed = max( 0.01, self.e_greed - self.e_greed_decrement) return act def predict(self, obs): obs = np.expand_dims(obs, axis=0) pred_Q = self.fluid_executor.run( self.pred_program, feed={'obs': obs.astype('float32')}, fetch_list=[self.value])[0] pred_Q = np.squeeze(pred_Q, axis=0) act = np.argmax(pred_Q) return act def learn(self, obs, act, reward, next_obs, terminal): if self.global_step % self.update_target_steps == 0: self.alg.sync_target() self.global_step += 1 act = np.expand_dims(act, -1) feed = { 'obs': obs.astype('float32'), 'act': act.astype('int32'), 'reward': reward, 'next_obs': next_obs.astype('float32'), 'terminal': terminal } cost = self.fluid_executor.run( self.learn_program, feed=feed, fetch_list=[self.cost])[0] return cost class ReplayMemory(object): def __init__(self, max_size): self.buffer = collections.deque(maxlen=max_size) def append(self, exp): self.buffer.append(exp) def sample(self, batch_size): mini_batch = random.sample(self.buffer, batch_size) obs_batch, action_batch, reward_batch, next_obs_batch, done_batch = [], [], [], [], [] for experience in mini_batch: s, a, r, s_p, done = experience obs_batch.append(s) action_batch.append(a) reward_batch.append(r) next_obs_batch.append(s_p) done_batch.append(done) return np.array(obs_batch).astype('float32'), \ np.array(action_batch).astype('float32'), np.array(reward_batch).astype('float32'),\ np.array(next_obs_batch).astype('float32'), np.array(done_batch).astype('float32') def __len__(self): return len(self.buffer) def init_bo(): for i in range(0,_n): cw[i]=_cwmin bo[i]=random.randint(0,_cwmax)%cw[i] #print("cw[",i,"]=",cw[i]," bo[",i,"]=",bo[i]) def Trts(): time=192+(20*8)/1 return time def Tcts(): time=192+(14*8)/1 return time def Tdata(): global rate time=192+((_pktSize+28)*8.0)/rate return time def Tack(): time=192+(14*8.0)/1 return time def getMinBoAllStationsIndex(): index=0 min=bo[index] for i in range(0,_n): if bo[i]<min: index=i min=bo[index] return index def getCountMinBoAllStations(min): count=0 for i in range(0,_n): if(bo[i]==min): count+=1 return count def subMinBoFromAll(min,count): global _cwmin, _cwmax, cwthreshold for i in range(0,_n): if bo[i]<min: print("<Error> min=",min," bo=",bo[i]) exit(1) if(bo[i]>min): bo[i]-=min elif bo[i]==min: if count==1: if (cw[i]> cwthreshold): cw[i]-=32 elif (cw[i]>_cwmin): cw[i]= cw[i]/2 else: cw[i]=_cwmin; bo[i] = random.randint(0, _cwmax) % cw[i] elif count>1: if (cw[i]<cwthreshold): cw[i]*=2 elif (cw[i]<_cwmax): cw[i]+=32; else: cw[i]=_cwmax bo[i] = random.randint(0, _cwmax) % cw[i] else: print("<Error> count=",count) exit(1) def setStats(min,index,count): global stat_succ,stat_coll if count==1: stat_pkts[index]+=1 stat_succ+=1 else: stat_coll+=1 for i in range(0,_n): if bo[i]<min: print("<Error> min=", min, " bo=", bo[i]) exit(1) #elif bo[i]==min: # print("Collision with min=", min) def setNow(min,count): global M, now, SIFS, DIFS, EIFS, SLOT if rtsmode==1: now+=Trts()/M; if count==1: if(rtsmode==1): now+=SIFS/M now+=Tcts()/M now+=SIFS/M now+=DIFS/M now+=min*SLOT/M now+=Tdata()/M now+=SIFS/M now+=Tack()/M elif count>1: if rtsmode==1: now+=EIFS/M now+=min*SLOT/M else: now+=EIFS/M now+=min*SLOT/M now+=Tdata()/M else: print("<Error> count=", count) exit(1) def new_resolve(new_cwthreshold): global cwthreshold cwthreshold=new_cwthreshold index=getMinBoAllStationsIndex() min=bo[index] count=getCountMinBoAllStations(min) setNow(min, count) setStats(min, index, count) subMinBoFromAll(min, count) def printStats(): print("\nGeneral Statistics\n") print("-"*50) print("stat_succ:",stat_succ,"stat_coll:",stat_coll) print("Collision rate:", stat_coll/(stat_succ+stat_coll)*100, "%") print("Aggregate Throughput:", (stat_succ)*(_pktSize*8.0)/now) def main(): global _n, now, _simTime, stat_succ, stat_coll, pre_stat_succ, pre_stat_coll, _pktSize, pre_time pre_collision_rate=0.0 random.seed(1) np.random.seed(1) init_bo() obs_dim=2 act_dim=8 print("obs_dim=",obs_dim,"act_dim=",act_dim) model = Model(act_dim=act_dim) algorithm = DQN(model, act_dim=act_dim, gamma=GAMMA, lr=LEARNING_RATE) agent = Agent( algorithm, obs_dim=obs_dim, act_dim=act_dim, e_greed=0.1, e_greed_decrement=1e-6) rpm = ReplayMemory(MEMORY_SIZE) #save_path = './dnq_model.ckpt' #if os.path.isfile(save_path): # agent.restore(save_path) step=0 reward=0.0 state = [0.0, 0.0] show=0 while now < _simTime: while len(rpm) < MEMORY_WARMUP_SIZE: obs = np.array(state) action = agent.sample(obs) new_cwthreshold = 128*(1+action) t1=now while True: new_resolve(new_cwthreshold) if now - t1 > 0.1: break
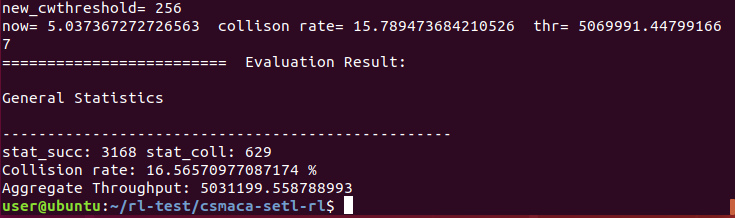
collision_rate = (stat_coll - pre_stat_coll) / (stat_succ + stat_coll - pre_stat_succ - pre_stat_coll) * 100 thr = (stat_succ - pre_stat_succ) * (_pktSize * 8.0) / (now - pre_time) reward = thr / rate / M next_state=[] next_state.append(collision_rate) next_state.append(pre_collision_rate) #step += 1 pre_stat_succ = stat_succ pre_stat_coll = stat_coll pre_collision_rate = collision_rate pre_time = now #print("now=", now, " collison rate=",collision_rate," thr=", thr) next_obs=np.array(next_state) done = False rpm.append((obs, action, reward, next_obs, done)) #print("len(rpm)=", len(rpm), "obs=", obs, " action=", action, " next_obs=", next_obs, " reward=", reward) state = next_state #if step>=5: # exit() if step%5==0: (batch_obs, batch_action, batch_reward, batch_next_obs, batch_done) = rpm.sample(BATCH_SIZE) train_loss = agent.learn(batch_obs, batch_action, batch_reward, batch_next_obs, batch_done) #print("agent.learn() is called, train_loss=", train_loss) obs = np.array(state) action = agent.sample(obs) new_cwthreshold = 128*(1+action) t1=now while True: new_resolve(new_cwthreshold) if now - t1 > 0.1: break collision_rate = (stat_coll - pre_stat_coll) / (stat_succ + stat_coll - pre_stat_succ - pre_stat_coll) * 100 thr = (stat_succ - pre_stat_succ) * (_pktSize * 8.0) / (now - pre_time) reward = thr / rate / M next_state = [] next_state.append(collision_rate) next_state.append(pre_collision_rate) step += 1 pre_stat_succ = stat_succ pre_stat_coll = stat_coll pre_collision_rate = collision_rate pre_time = now # print("now=", now, " collison rate=",collision_rate," thr=", thr) next_obs = np.array(next_state) done = False rpm.append((obs, action, reward, next_obs, done)) if now > show: print("now=", now, "obs=", obs, " action=", action, " next_obs=", next_obs, " reward=", reward) show+=100 state = next_state printStats() #agent.save(save_path) #evalution now=pre_time=0.0 state = [0.0, 0.0] stat_coll=pre_stat_coll=0 stat_succ=pre_stat_succ=0 stat_pkts=np.zeros(_n) while now < 5: obs = np.array(state) action = agent.predict(obs) new_cwthreshold = 128*(1+action) print("new_cwthreshold=", new_cwthreshold)
t1=now while True: new_resolve(new_cwthreshold) if now - t1 > 0.1: break collision_rate = (stat_coll - pre_stat_coll) / (stat_succ + stat_coll - pre_stat_succ - pre_stat_coll) * 100 thr = (stat_succ - pre_stat_succ) * (_pktSize * 8.0) / (now - pre_time) next_state = [] next_state.append(collision_rate) next_state.append(pre_collision_rate) pre_stat_succ = stat_succ pre_stat_coll = stat_coll pre_collision_rate = collision_rate pre_time = now print("now=", now, " collison rate=",collision_rate," thr=", thr) state = next_state print("="*25, " Evaluation Result:") printStats() main() |
Execution
……………………….
Last Modified: 2022/2/5
Dr. Chih-Heng Ke
Department
of Computer Science and Information Engineering, National Quemoy
University, Kinmen, Taiwan
Email:
smallko@gmail.com