Move to Right [ns3-gym, reinforcement learning (Q-Learning) example]
[Description]
An agent is located at position 0 (state=0) that is trying to move to position 5 (state=5). The agent can move to left (action=0) or move to right (action=1). When the agent reaches the position 5 (state=5), the agent can get the reward 1.0. Otherwise, the agent gets nothing (reward=0.0). I will show how to use q-learning to make the agent move to right as fast as possible.
Note. If you want to run this example, you need to install ns3-gym first. Then create a directory named move2right under scratch. Put the following codes in this directory.
[sim.c]
|
/* -*- Mode: C++; c-file-style:
"gnu"; indent-tabs-mode:nil; -*- */ /* * Copyright (c) 2018 Piotr Gawlowicz * * This program is free software; you
can redistribute it and/or modify * it under the terms of the GNU General
Public License version 2 as * published by the Free Software
Foundation; * * This program is distributed in the
hope that it will be useful, * but WITHOUT ANY WARRANTY; without
even the implied warranty of * MERCHANTABILITY or FITNESS FOR A
PARTICULAR PURPOSE. See the * GNU General Public License for more
details. * * You should have received a copy of
the GNU General Public License * along with this program; if not,
write to the Free Software * Foundation, Inc., 59 Temple Place,
Suite 330, Boston, MA 02111-1307 USA * * Author: Piotr Gawlowicz
<gawlowicz.p@gmail.com> * */ #include "ns3/core-module.h" #include "ns3/opengym-module.h" using namespace ns3; NS_LOG_COMPONENT_DEFINE ("OpenGym"); int mypos=0; int myact; /* Define observation space */ Ptr<OpenGymSpace> MyGetObservationSpace(void) {
uint32_t nodeNum = 1;
uint32_t low = 0;
uint32_t high = 5;
std::vector<uint32_t> shape = {nodeNum,};
std::string dtype =
TypeNameGet<uint32_t> ();
Ptr<OpenGymBoxSpace>
space = CreateObject<OpenGymBoxSpace>
(low, high, shape, dtype);
NS_LOG_UNCOND ("MyGetObservationSpace:
" << space);
return space; } /* Define action space */ Ptr<OpenGymSpace> MyGetActionSpace(void) {
uint32_t nodeNum = 2;
Ptr<OpenGymDiscreteSpace>
space = CreateObject<OpenGymDiscreteSpace>
(nodeNum);
NS_LOG_UNCOND ("MyGetActionSpace:
" << space);
return space; } /* Define game over condition */ bool MyGetGameOver(void) {
bool isGameOver = false;
static float stepCounter = 0.0;
stepCounter += 1;
if (mypos==5) { isGameOver = true;
}
NS_LOG_UNCOND ("MyGetGameOver: "
<< isGameOver << " stepCounter:"<< stepCounter);
return isGameOver; } /* Collect observations */ Ptr<OpenGymDataContainer> MyGetObservation(void) {
uint32_t nodeNum = 1;
std::vector<uint32_t> shape = {nodeNum,};
Ptr<OpenGymBoxContainer<uint32_t>
> box = CreateObject<OpenGymBoxContainer<uint32_t>
>(shape);
box->AddValue(mypos);
NS_LOG_UNCOND ("Now:" << Simulator::Now
().GetSeconds () << " MyGetObservation: " << box);
return box; } /* Define reward function */ float MyGetReward(void) {
float reward = 0.0;
if(mypos==5) reward=1.0;
NS_LOG_UNCOND ("MyGetReward:"
<< reward);
return reward; } /* Define extra info. Optional */ std::string MyGetExtraInfo(void) {
std::string myInfo
= "testInfo";
myInfo += "|123";
NS_LOG_UNCOND("MyGetExtraInfo:
" << myInfo);
return myInfo; } /* Execute received actions */ bool MyExecuteActions(Ptr<OpenGymDataContainer>
action) {
Ptr<OpenGymDiscreteContainer>
discrete = DynamicCast<OpenGymDiscreteContainer>(action);
myact=discrete->GetValue();
if(myact==1){ mypos+=1;
} else { if (mypos==0) mypos=0; else mypos-=1;
}
NS_LOG_UNCOND ("MyExecuteActions:
" << myact);
return true; } void ScheduleNextStateRead(double
envStepTime, Ptr<OpenGymInterface> openGym) {
Simulator::Schedule (Seconds(envStepTime), &ScheduleNextStateRead,
envStepTime, openGym);
openGym->NotifyCurrentState(); } int main (int argc,
char *argv[]) {
// Parameters of the scenario
uint32_t simSeed = 1;
double simulationTime = 10; //seconds
double envStepTime = 0.1; //seconds, ns3gym
env step time interval
uint32_t openGymPort = 5555;
uint32_t testArg = 0;
CommandLine cmd;
// required parameters for OpenGym interface
cmd.AddValue
("openGymPort", "Port number for OpenGym env. Default: 5555", openGymPort);
cmd.AddValue
("simSeed", "Seed for random
generator. Default: 1", simSeed);
// optional parameters
cmd.AddValue
("simTime", "Simulation time in
seconds. Default: 10s", simulationTime);
cmd.AddValue
("testArg", "Extra simulation
argument. Default: 0", testArg);
cmd.Parse (argc, argv);
NS_LOG_UNCOND("Ns3Env
parameters:");
NS_LOG_UNCOND("--simulationTime:
" << simulationTime);
NS_LOG_UNCOND("--openGymPort:
" << openGymPort);
NS_LOG_UNCOND("--envStepTime:
" << envStepTime);
NS_LOG_UNCOND("--seed: " << simSeed);
NS_LOG_UNCOND("--testArg:
" << testArg);
RngSeedManager::SetSeed (1);
RngSeedManager::SetRun (simSeed);
// OpenGym Env
Ptr<OpenGymInterface>
openGym = CreateObject<OpenGymInterface> (openGymPort);
openGym->SetGetActionSpaceCb( MakeCallback (&MyGetActionSpace)
);
openGym->SetGetObservationSpaceCb( MakeCallback (&MyGetObservationSpace)
);
openGym->SetGetGameOverCb( MakeCallback (&MyGetGameOver)
);
openGym->SetGetObservationCb( MakeCallback (&MyGetObservation)
);
openGym->SetGetRewardCb( MakeCallback (&MyGetReward)
);
openGym->SetGetExtraInfoCb( MakeCallback (&MyGetExtraInfo)
);
openGym->SetExecuteActionsCb( MakeCallback (&MyExecuteActions)
);
Simulator::Schedule (Seconds(0.0), &ScheduleNextStateRead, envStepTime,
openGym);
NS_LOG_UNCOND ("Simulation start");
Simulator::Stop (Seconds (simulationTime));
Simulator::Run ();
NS_LOG_UNCOND ("Simulation stop");
openGym->NotifySimulationEnd();
Simulator::Destroy (); } |
[q-learning.py]
|
#!/usr/bin/env
python3 # -*- coding: utf-8 -*- import argparse from ns3gym import ns3env import numpy as
np import pandas as pd N_STATES = 6
# the length of the 1 dimensional world ACTIONS = ['left', 'right'] # available actions EPSILON = 0.9 # greedy police ALPHA = 0.1 # learning rate GAMMA = 0.9 # discount factor MAX_EPISODES = 5 # maximum episodes FRESH_TIME = 0.1 # fresh time for one move parser = argparse.ArgumentParser(description='Start
simulation script on/off') parser.add_argument('--start',
type=int,
default=1,
help='Start ns-3 simulation script 0/1, Default: 1') parser.add_argument('--iterations',
type=int,
default=MAX_EPISODES,
help='Number of iterations, Default: 10') args = parser.parse_args() startSim = bool(args.start) iterationNum = int(args.iterations) port = 5555 simTime = 10 # seconds stepTime = 0.1
# seconds seed = 0 simArgs = {"--simTime": simTime,
"--testArg": 123} debug = False env = ns3env.Ns3Env(port=port,
stepTime=stepTime, startSim=startSim, simSeed=seed, simArgs=simArgs, debug=debug) # simpler: #env = ns3env.Ns3Env() env.reset() ob_space = env.observation_space ac_space = env.action_space print("Observation space: ", ob_space, ob_space.dtype) print("Action space: ", ac_space, ac_space.dtype) stepIdx = 0 currIt = 0 def build_q_table(n_states,
actions): table = pd.DataFrame( np.zeros((n_states,
len(actions))), # q_table initial values
columns=actions, # actions's
name ) # print(table) # show table return table def choose_action(state, q_table): # This is how to choose an
action state_actions
= q_table.iloc[state, :] #print("q_table=", q_table) #print("state_actions=", state_actions) if (np.random.uniform() > EPSILON) or ((state_actions == 0).all()): # act non-greedy or state-action have
no value action_name = np.random.choice(ACTIONS) #print("action_name1=", action_name) else: # act greedy action_name = state_actions.idxmax() # replace argmax to idxmax as argmax means a different function in newer
version of pandas #print("action_name2=", action_name) return action_name try: q_table
= build_q_table(N_STATES, ACTIONS) print("q_table=", q_table) while True: print("Start iteration: ", currIt) obs = env.reset() print("Step: ", stepIdx) print("---obs:", obs, " type(obs[0])=",
type(obs[0]), " obs[0]=",
obs[0])
while True: stepIdx += 1
A = choose_action(obs[0], q_table)
if A == 'right':
action=1
else:
action=0
print("---action: ", action)
print("Step: ", stepIdx)
next_obs, reward, done, info = env.step(action)
print("---next_obs,
reward, done, info: ", next_obs, reward, done,
info)
#print("111 q_table=",
q_table)
q_predict = q_table.loc[obs[0],
A]
#print("q_predict=",
q_predict)
if next_obs != 5:
q_target = reward + GAMMA * q_table.iloc[next_obs[0],
:].max()
#print("q_target=",
q_target, " reward=", reward)
#print("q_table.iloc[next_obs[0], :].max()=", q_table.iloc[next_obs[0], :].max())
else:
q_target = reward # next state is
terminal
#print("q_target=",
q_target)
q_table.loc[obs[0], A] += ALPHA * (q_target - q_predict) # update
#print("222 q_table=",
q_table)
obs = next_obs # move to next state
if done:
print("iteration ", currIt, " stepIdx=", stepIdx, " done")
print("q_table=",
q_table)
stepIdx = 0
if currIt + 1 < iterationNum:
env.reset()
break
currIt += 1 if
currIt == iterationNum:
break except KeyboardInterrupt: print("Ctrl-C
-> Exit") finally: env.close() print("Done") |
[Execution]
Open one terminal.
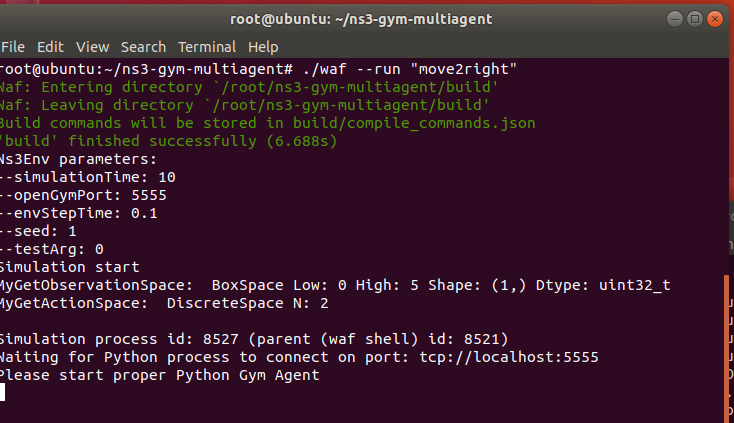
Open another terminal

Then you can see
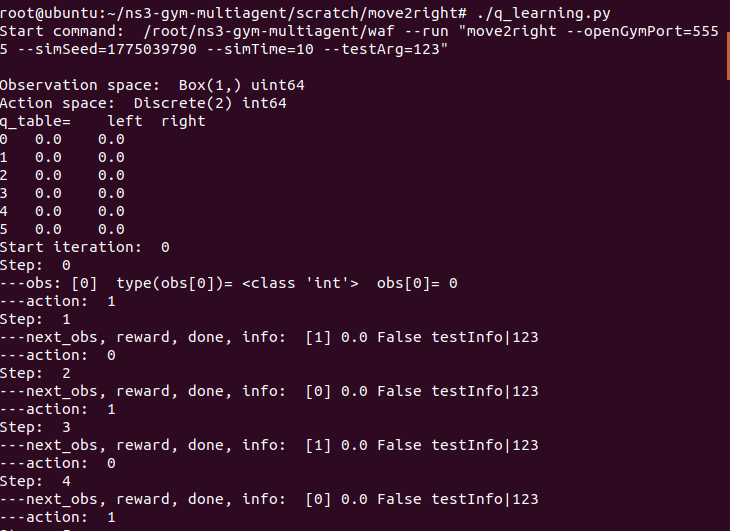
…………………………………………..
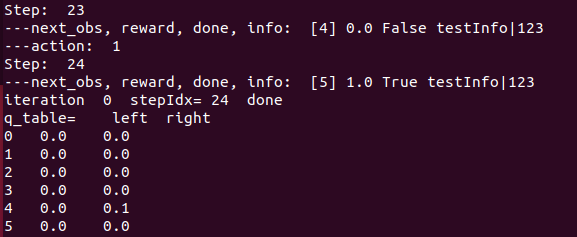
(first run, we need 24 steps to finish the jobs.)
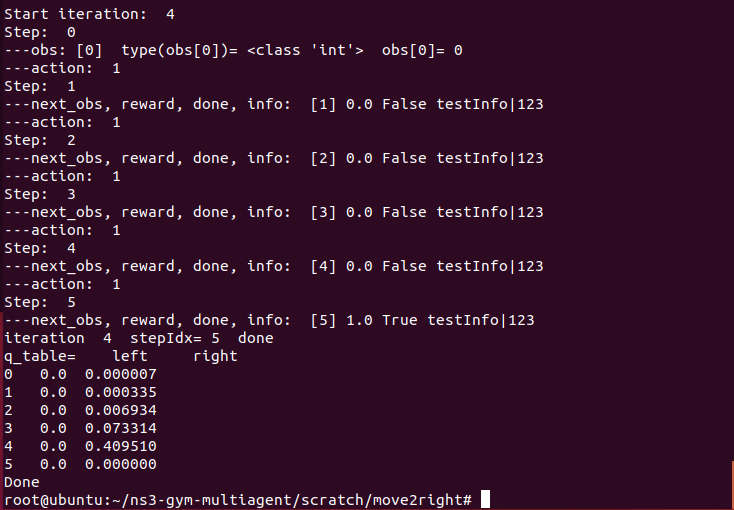
After few runs, we can see that the agent can reaches position 5 with only 5 moves. We can also see the q table.
Last
Modified: 2022/11/15 done
[Author]
Dr. Chih-Heng Ke
Department of Computer
Science and Information Engineering, National Quemoy University, Kinmen,
Taiwan
Email: smallko@gmail.com